suppressPackageStartupMessages(library(tidyverse))
words <-
read_csv(
file = "five-letters.csv",
col_names = FALSE
) |>
rename("word" = X1) |>
mutate(word = str_to_lower(word)) |>
mutate(
l1 = str_sub(string = word, start = 1, end = 1),
l2 = str_sub(string = word, start = 2, end = 2),
l3 = str_sub(string = word, start = 3, end = 3),
l4 = str_sub(string = word, start = 4, end = 4),
l5 = str_sub(string = word, start = 5, end = 5)
)
wordsUnderstanding the data
Let’s start by getting the ~500 most commonly-occurring five-letter words (that I downloaded as a csv file from the internet).
For reference, I’ll also chart the popularity of each letter by their order in these five-letter words.
words_long <- words |>
pivot_longer(
cols = -word,
names_to = "measure",
values_to = "values"
) |>
mutate(
position = as.integer(
str_sub(string = measure, start = 2)
)
) |>
select(values, position)
words_long |>
count(values, position) |>
mutate(
position = case_match(
position,
1 ~ "1st",
2 ~ "2nd",
3 ~ "3rd",
4 ~ "4th",
5 ~ "5th"
)
) |>
ggplot(
aes(
x = values,
y = n,
fill = values %in% c("a", "e", "r", "s", "t")
)
) +
geom_col() +
scale_y_continuous(
limits = c(0, NA),
minor_breaks = NULL,
expand = expansion(mult = 0, add = 1)
) +
scale_fill_manual(values = c("#edd9c0", "#63431c")) +
facet_wrap(~position, nrow = 1) +
theme_minimal() +
labs(
title = "Frequency of letter by word order",
subtitle = "Emphasis on the letters a, e, r, s and t\n",
x = NULL,
y = NULL
) +
theme(
legend.position = "none",
plot.title.position = "plot"
)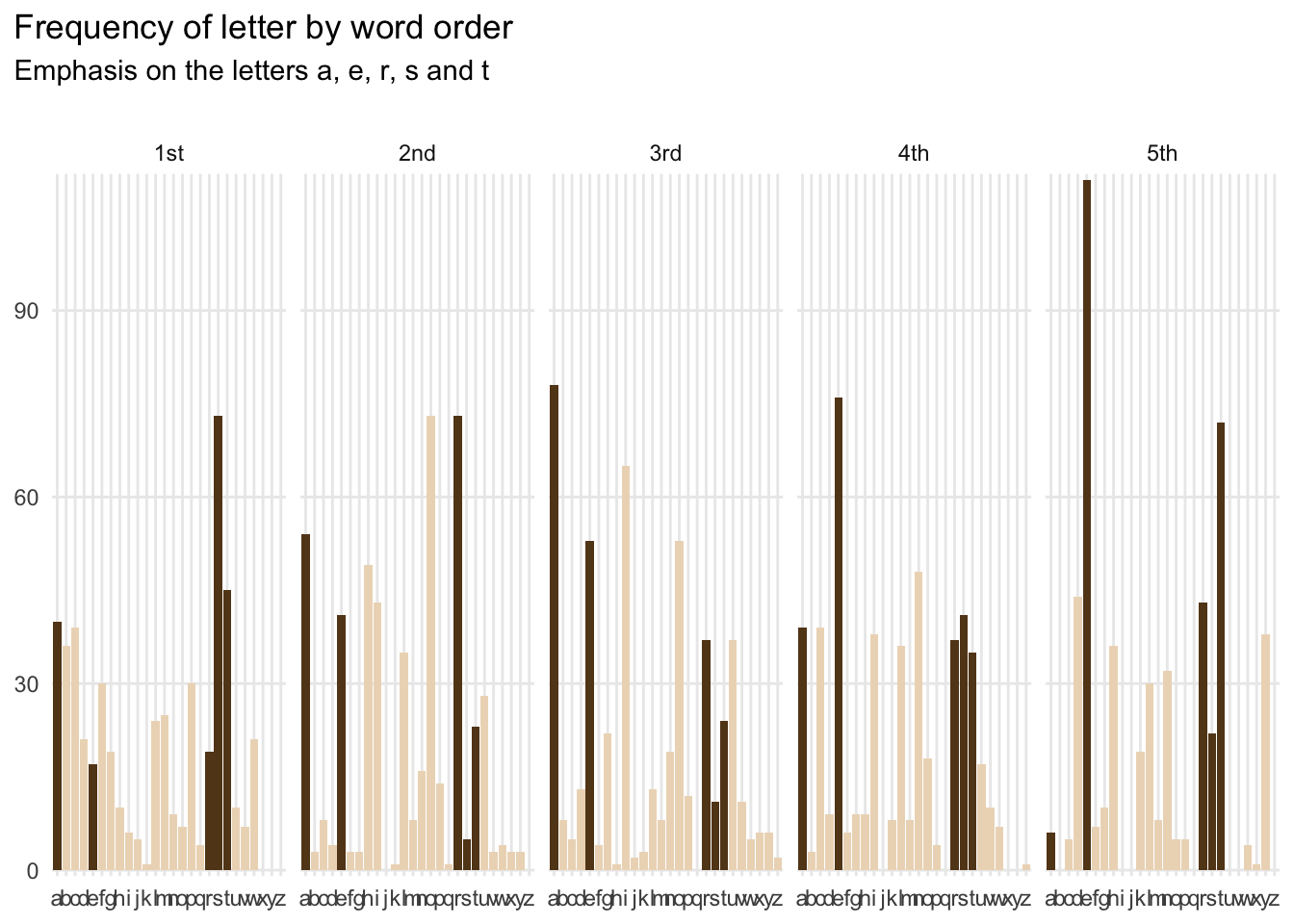
As you can see from the emphasis, some of these letters appear a lot more than others, and especially at the start and end of the word.
Finding the best first guess
As Wordle tells you if your letters are in the word and in the correct position, I’ll treat the latter as more important than the former. My train journey wasn’t long enough for me to delve deeper, so I assumed that it is doubly good to guess a letter in the right position than it is to guess a correct letter in any position. Given the way that my brain works, I find it easier to guess a word if I know the first and last letter, so I’ll award correct guesses in these positions with 50% more kudos than those in other positions.
If I incorporate all these preferences — and remove words where a letter occurs more than once — the following words become the best options for a first guess at Wordle.
multiplier_bonus <- 2
multiplier_edge <- 1.5
frequency <- words_long |>
count(values, position) |>
arrange(values, position) |>
pivot_wider(
id_expand = TRUE,
names_from = position,
values_from = n,
values_fill = 0
) |>
select(values, "f1" = `1`, "f2" = `2`, "f3" = `3`, "f4" = `4`, "f5" = `5`) |>
mutate(f0 = f1 + f2 + f3 + f4 + f5)
results <- words |>
left_join(frequency |> select(values, f1, f0), by = c("l1" = "values")) |>
rename("a1" = "f0") |>
left_join(frequency |> select(values, f2, f0), by = c("l2" = "values")) |>
rename("a2" = "f0") |>
left_join(frequency |> select(values, f3, f0), by = c("l3" = "values")) |>
rename("a3" = "f0") |>
left_join(frequency |> select(values, f4, f0), by = c("l4" = "values")) |>
rename("a4" = "f0") |>
left_join(frequency |> select(values, f5, f0), by = c("l5" = "values")) |>
rename("a5" = "f0") |>
mutate(
precise = f1 + f2 + f3 + f4 + f5,
bonus = (multiplier_edge * f1) + f2 + f3 + f4 + (multiplier_edge * f5),
general = a1 + a2 + a3 + a4 + a5,
total = (multiplier_bonus * bonus) + general
) |>
arrange(desc(total))
results_tidy <- results |>
select(word, l1:l5) |>
pivot_longer(cols = l1:l5, names_to = "value_letter", values_to = "values") |>
select(word, values) |>
distinct() |>
summarise(duplicates = n() != 5, .by = word) |>
filter(!duplicates) |>
left_join(results, by = join_by(word == word)) |>
select(word, total, bonus, general, l1:l5)
results_tidyIn other words, the best first guess at Wordle is stare. That shouldn’t be a surprise, as the chart above shows many occasions where s, t, a, r and e occur in five-letter words. Even better, s is the most frequent start to a word and e is the most common end letter in these words, giving the word a lot of ‘bonus’ points.
Finding the best subsequent guesses
Given that I’ve already chosen stare, what is the best second guess?1
attempt1 <- c("s", "t", "a", "r", "e")
results_tidy |>
filter(
!(l1 %in% attempt1),
!(l2 %in% attempt1),
!(l3 %in% attempt1),
!(l4 %in% attempt1),
!(l5 %in% attempt1)
)In this case, it looks to be child. And I can use a similar approach to find the best third guess, which turns out to be funky.
attempt2 <- c("s", "t", "a", "r", "e", "c", "h", "i", "l", "d")
results_tidy |>
filter(
!(l1 %in% attempt2),
!(l2 %in% attempt2),
!(l3 %in% attempt2),
!(l4 %in% attempt2),
!(l5 %in% attempt2)
)Whilst I could have continued with the analysis, my train journey didn’t permit it. I was therefore left with the following best guesses, expressed as the following mnemonic:
STARE at the CHILD that is FUNKY
👀 🧒🏻 😎
UPDATE in July 2023: It turns out that the mnemonic above is successful strategy, as it has given me a winning streak of 201 days (and counting).
Footnotes
These ‘best’ guesses might not be perfect, as my assumptions above and the approach in general could probably be improved, perhaps with Operational Research techniques. That said, I suspect that ‘stare’ and the next guesses are decent approximations to the ideal solution.↩︎